
5月25日、グーグル傘下のDeepMindが開発したAI「AlphaGo」(アルファゴ)が中国烏鎮で開催された「The Future of Go Summit」で、世界最強囲碁棋士・柯潔(カケツ)氏と対局しました。結果は、3対0でAlphaGoが圧勝。
私は囲碁の知識はほぼゼロですが、その昔、プロのゲーム制作者を目指していたこともあり、「AlphaGoが一体、どういうプログラムで作られているのか」にとても興味を持ちました。
AlphaGoがプロ棋士に勝てた理由について、できるだけ数学的な説明は避けて、直感的に「ゆるーくわかる」を目指して解説したいと思います。(『ウォーレン・バフェットに学ぶ!1分でわかる株式投資~雪ダルマ式に資産が増える52の教え~』東条雅彦)
囲碁も投資も人間以上!? 人工知能の最前線をざっくり理解しよう
最後の砦「囲碁」でも人間はコンピュータに負けてしまった
5月25日、グーグル傘下のDeepMindが開発したAI「AlphaGo(アルファゴ)」が中国烏鎮で開催された「The Future of Go Summit」で、世界最強囲碁棋士・柯潔(カケツ)氏と対局しました。
結果は、3対0でAlphaGoが圧勝。去年、李世ドル(イ・セドル)氏がAlphaGoに負けるのを見て、柯潔氏は「AlphaGoは李世ドルに勝っても、俺には勝てない」と強気の発言をしていました。しかし、結果は完敗でした。
AlphaGoは1日に100万局ぐらいを対局して自己学習をしており、去年よりも圧倒的に強くなっていました。李世ドル氏に9勝している柯潔氏でも、まったく歯が立たなかったのです。
<参考>『コンピューター vs. 人間』の歴史
オセロ:(1997年)Logistelloが世界チャンピオン村上健に勝利
チェス:(1997年)IBMのDeep Blueが世界チャンピオン ガルリ・カスパロフに勝利
将棋 :(2013年4月)第2回将棋電王戦にて、GPS将棋がA級棋士 三浦弘行八段に勝利
囲碁 :(2016年3月)AlphaGoがイ・セドル九段に勝利
:(2017年5月)AlphaGoがカ・ケツ九段に勝利
コンピューターが苦戦する要因「探索空間の大きさ」
なぜ、これまで囲碁はコンピュータよりも人間の方が有利だったのでしょうか? 最も大きな要因は、「探索空間の大きさ」です。
<探索空間の大きさ>
オセロ:10の60乗
チェス:10の120乗
将棋 :10の220乗
囲碁 :10の360乗
例としてチェスと囲碁を比べてみると、コンピューターから見た場合の処理負荷の違いは一目瞭然です。
<チェス>
最初の一手は、先手の白は20通り、後手の黒も20通りである。両者が最初の一手を打ち終わった時に現れる盤面の形は20×20で400通りになる。
<囲碁>
盤面に描かれた縦横19本ずつの直線の交差点361個の1つに先手の黒を打つ。後手の白の打ち方は360通りである。両者が最初の一手を打ち終わった時に現れる盤面の形は361×360で129,960通りになる。
仮に6手先を読むことにすると、次のような計算式になります。
<チェスの枝別れ総数>
20×20×20×20×20×20=64,000,000通り
<囲碁の枝別れ総数>
361×360×359×358×357×356=2,122,781,978,399,040通り
囲碁の6手先の枝別れ総数は、2千兆を超えます。枝別れ総数が多ければ多い程、コンピューターの処理に負荷がかかります。
元々、囲碁でコンピューターが人間に勝てるまでに、あと10年かかると言われていました。枝分かれ総数がほぼ無限大に広がるため、コンピューターの処理能力では間に合わなかったのです。人間が一手を打つ度に、コンピューターの方が「うーん」と唸って、1週間後に次の一手を打ち返すようだと対局になりません。
チェスでは1997年にIBMのDeep Blueが世界チャンピオンのガルリ・カスパロフに勝利していますが、チェスと囲碁ではまったく前提条件が異なります。Deep Blueはコンピューターの処理能力を極限まで高める力技で押し切りましたが、囲碁では力技だけでは人間には勝てません。
AI革命の到来を予感させるAphaGoの完全勝利
囲碁のトップ棋士達も、全ての手を読み切って打っているわけではありません。囲碁は全ての手を読み切れないため、他のゲームよりも「思考」の比重が圧倒的に大きいという特徴を持っています。
プロの棋士ですら、相手の手筋を読み切れないので、(論理的には説明不可能な)閃きに似た力も活用しながら、打っていると言われています。
コンピューターが囲碁で勝とうとした場合、「計算」だけではなく、人間と同じように「思考」という領域に踏み込まなければいけません。
<人間とコンピューターの得意不得意>
単純計算…コンピューターの方が得意
思考…人間の方が得意
今回、AlphaGoを勝利に導いたのが、「モンテカルロ木探索」の発明だと言われています。
従来の探索アルゴリズムは、開発者側が予め作った評価関数(最善手を探すための処理)に基づいて最善手を導き出すという方法でした。ところが、モンテカルロ木探索は、コンピューターの内部でランダムシミュレーションを行った結果を元に最善手を導き出します。「ランダム」に探すという所がポイントです。
<モンテカルロ木探索のイメージ>
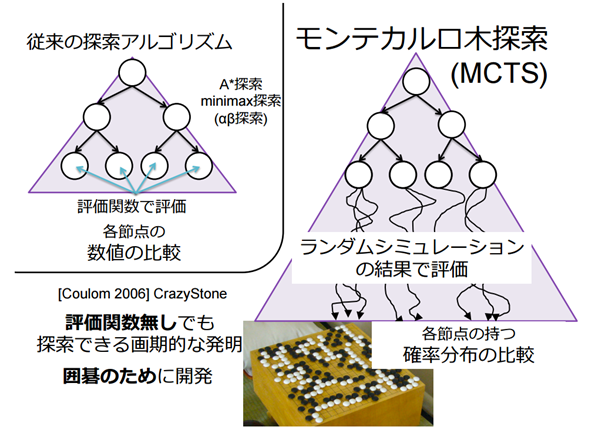
出典:『モンテカルロ木探索の理論と実践』美添一樹氏
評価関数なしでも探索できるモンテカルロ木探索の発明によって、コンピューターは擬似的に人間の思考に近づくことができたのです。
-
=田渕直也")
人間はAIに敗れるか?投資の世界に訪れるシンギュラリティ(技術的特異点)=田渕直也
-

ウェンディーズやマクドナルドから「店員のスマイル」が完全消滅する日
-

テクノロジー4.0が生む「新しい格差」誰が得して誰が損するのか?=大前研一
-

今年の主役はNYダウとビットコイン、そして…?未来予測プログラムが分析=高島康司
-

アマゾンが世界中のお買い物から「注文手続き」をなくす日=三浦茜
-

アマゾンのAI食料品店『Amazon Go』はあと5年で世界を何色に塗り替えるか?=吉田繁治
-

天才投資家ジョージ・ソロスの「再帰性理論」をもっと分かりやすく!=東条雅彦
-

トレーダーを惑わせる「2つのランダム」 アルゴ取引は決定論の夢を見るか?=田渕直也
-

「銀」を買う者だけが生き残る?日銀の「神風特攻」に怯える世界経済
-

「ビットコインは怪しい」と思う日本人が知るべき仮想通貨の未来=俣野成敏
